Best LLMs for RAG: Top Open And Closed Source Models

Barely a day goes by without a new LLM being released. While private models continue to improve, enterprises are increasingly curious about whether open-source alternatives have caught up; specifically, they want to know if open-source models are robust enough to handle production-level Retrieval Augmented Generation (RAG) tasks.
Another growing concern in RAG is the significant cost of vector databases and whether it can be eliminated with long context RAG. To make your selection process easier, we’ve analyzed the top LLMs for RAG tasks, both open and closed source, with insights into their performance across different context lengths.
Types of RAG Tasks
RAG tasks involve using external data sources to generate more accurate and contextually relevant responses. The tasks can be categorized based on the length of the context they handle:
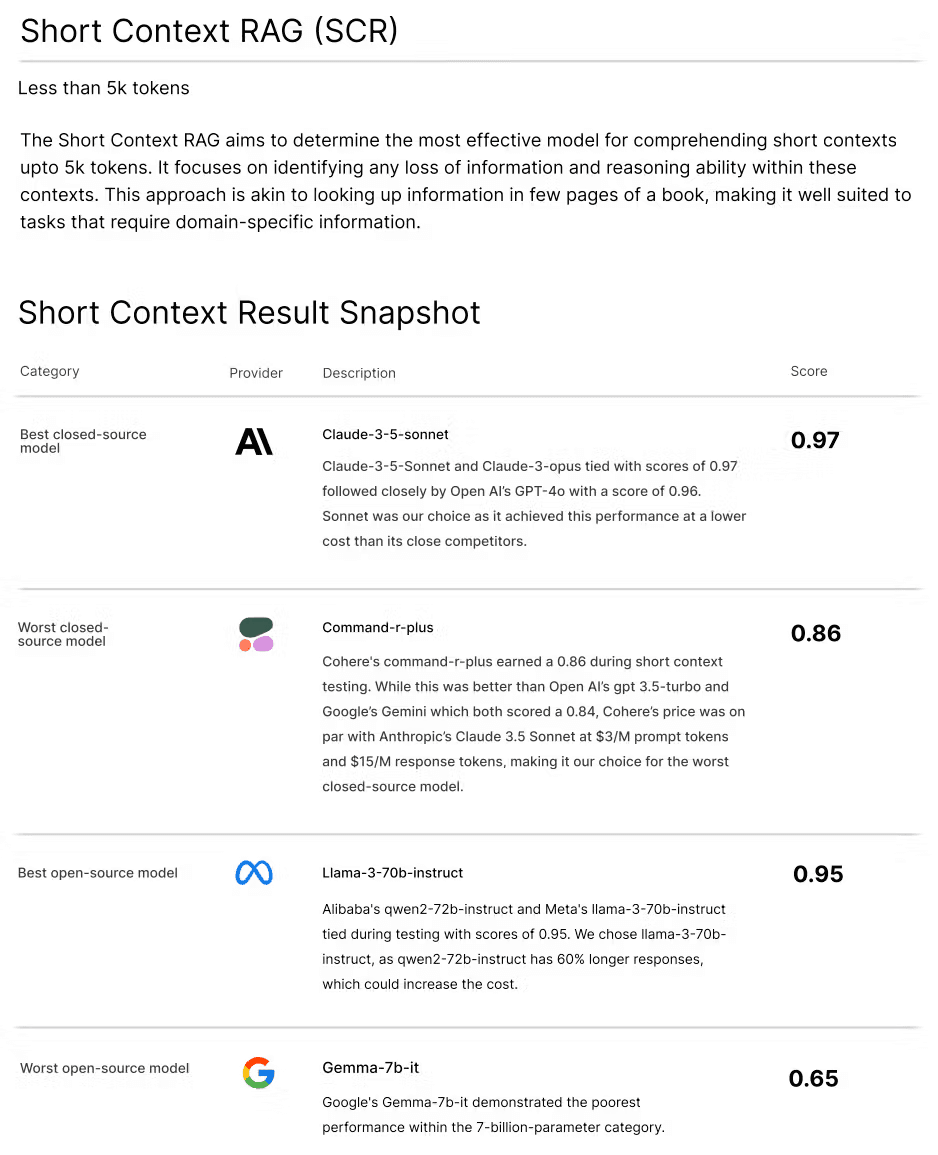
Short Context RAG (SCR)
SCR involves handling contexts of less than 5,000 tokens, akin to dealing with a few pages of a book. This task is suited for scenarios requiring quick, precise answers from a limited dataset. For example, customer support chatbots can benefit from SCR by quickly retrieving relevant information from a knowledge base.
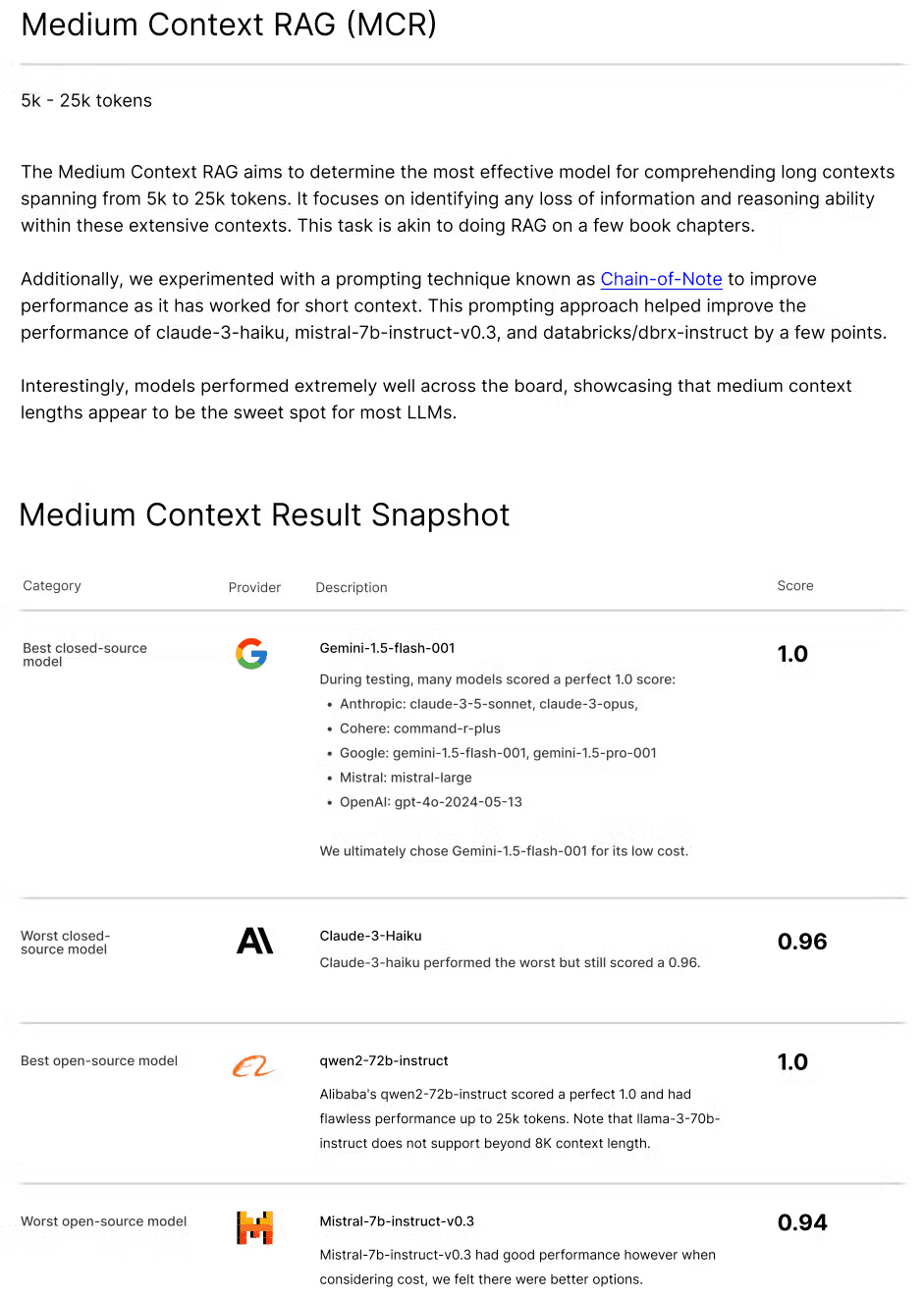
Medium Context RAG (MCR)
MCR deals with contexts ranging from 5,000 to 25,000 tokens, similar to processing a chapter of a book. It balances detail and scope, providing more nuanced answers without relying heavily on pinpoint accuracy of vector databases. This is useful in academic research where comprehensive understanding of a topic is required.
Medium context RAG experimented for - 5k, 10k, 15k, 20k, 25k
Long Context RAG (LCR)
LCR handles extensive contexts from 40,000 to 100,000 tokens, equivalent to processing an entire book. It offers rich information and comprehensive understanding but comes with higher computational costs and potential inclusion of irrelevant information. Legal document analysis is a prime example where LCR can be highly beneficial.
Long context RAG experimented for - 40k, 60k, 80k, 100k
Criteria for Selecting LLMs
We need a holistic evaluation methodology to select the best LLM for the task. Here are the criteria we use to measure LLM performance in RAG settings.

Benefits of Open Source LLMs
Open-source models offer a unique blend of performance, user satisfaction, cost efficiency, and security that can significantly impact an organization’s AI initiatives. Let’s look at these benefits in detail, using real-world examples to illustrate their impact.
Performance: Flexibility and Customization
One of the most compelling benefits of open-source LLMs is their flexibility. Unlike some closed-source models, open-source LLMs can be customized to meet specific needs. This flexibility allows organizations to fine-tune models for particular applications, leading to enhanced performance.
Scenario: Enhancing Customer Support
Consider a mid-sized tech company implementing an open-source LLM to improve its customer support system. Initially, the company faced challenges with response accuracy and relevance. By leveraging the open-source nature of the LLM, the company’s data science team customized the model to understand industry-specific terminology and customer queries better. This customization led to a 30% increase in first-contact resolution rates and significantly improved customer satisfaction.
Cost Efficiency: Lower Initial and Ongoing Costs
Open-source LLMs are generally more cost-effective than their closed-source counterparts. They eliminate licensing fees and reduce the total cost of ownership. Organizations can allocate resources more efficiently, investing in hardware, talent, and other critical areas.
Scenario: Digital Marketing
A digital marketing agency used fine-tuned Llama-3-70b-Chat to generate engaging content for various campaigns. The model’s high accuracy and ability to produce concise, relevant content helped the agency create compelling marketing materials quickly. The cost savings were substantial, and the return on investment was realized within the first year.
Control and Compliance
Security is a paramount concern for any organization. Open-source LLMs offer the advantage of greater control over the software. Organizations can audit the code, identify potential vulnerabilities, and implement security measures tailored to their specific requirements. This control is particularly important for industries with stringent compliance standards.
Scenario: Ensuring Compliance in Legal
A law firm integrated Qwen1.5-32B-Chat to help analyze large volumes of legal documents. The model’s ability to handle medium-length contexts enabled the firm to generate detailed summaries and insights from complex legal texts. This not only improved the efficiency of their legal research but also reduced the time spent on document review, allowing lawyers to focus on higher-value tasks. They implemented additional security layers and continuous monitoring to safeguard sensitive legal data. This approach enhanced security and ensured compliance with industry regulations, avoiding potential fines and reputational damage.
The Comprehensive Advantage
Combining these benefits, open-source LLMs provide a comprehensive advantage that can drive innovation and efficiency across various sectors. The ability to customize and optimize performance, cost savings, and enhanced security make open-source LLMs an attractive choice for forward-thinking organizations.
Evaluation Metric

We selected an LLM-based evaluation to keep the approach scalable. ChainPoll powers the context adherence used to evaluate SCR outputs for hallucination. It utilizes the strong reasoning abilities of GPTs and employs a technique of polling the model multiple times to assess the accuracy of the response. This approach not only quantifies the extent of potential errors but also provides an explanation based on the given context.
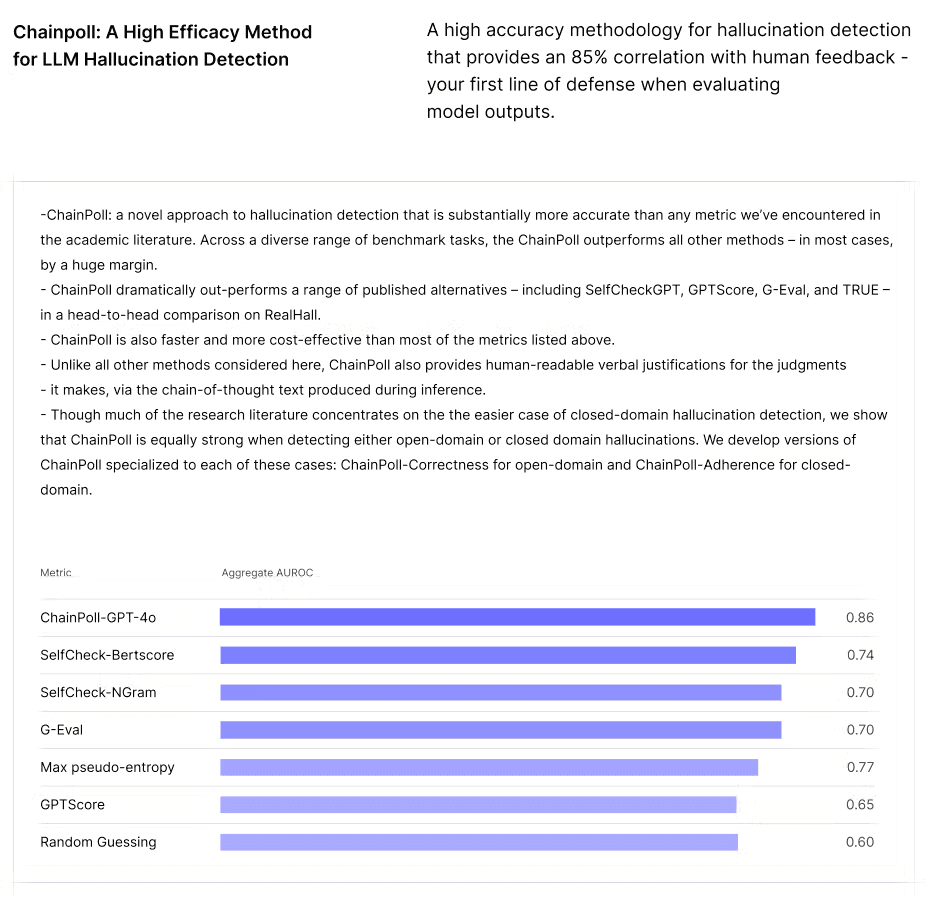
For medium and long context RAG, adherence to context is evaluated using a custom LLM-based assessment, checking for the relevant answer within the response.
Top LLMs for Short Context RAG
Top LLMs for Medium Context RAG
Top LLMs for Long Context RAG

Model Comparisons
One of our most insightful findings from experiments is that the Gemini 1.5 Flash offers an excellent balance between performance and cost. It achieved great context adherence scores of 0.94, 1, and 0.92 across short, medium, and long context task types, respectively.
Although Gemini-Flash is slightly behind GPT-4o, it accomplishes this at 1/14 of the cost. The cost per million prompt tokens is just $0.35 for Flash compared to $5 for GPT-4o. This makes Flash an outstanding choice for high-token-volume applications where a small margin of error is acceptable.
Here is a comparison between Flash and GPT-4o. You can compare any 2 of the 22 models on the hallucination index website.

How to Use Hallucination Index Rankings
It is human nature to select the highest-performing model for the task without considering the cost of implementation. But by selecting the model that best fits your needs, you can deliver high value at an affordable budget.
Large models, such as Llama-3-70b and GPT-4o, are engineered to tackle complex tasks that demand a deep understanding of nuanced language and heavy reasoning. These models deliver high accuracy and precision, making them indispensable for applications where the stakes are high and the margin for error is minimal. For example, their ability to comprehend and interpret intricate legal texts in legal analysis can streamline processes and enhance decision-making. Large models are also well-suited for large-scale deployments, supporting advanced AI research and addressing the needs of diverse user bases with varied queries.
On the other hand, SLMs (small language models) like Llama-3-8b are tailored for speed and efficiency. These models provide rapid responses while keeping computational costs low, making them a cost-effective and resource-efficient option for less complex tasks. SLMs are perfect for testing and prototyping, enabling fast experimentation without extensive computational resources.
While our model ranking offers valuable insights across various tasks, it doesn't cover every possible application and domain. To enhance our coverage, we plan to incorporate additional models and datasets in the future. Meanwhile, follow these steps to refine your model selection process.
Step 1: Task Alignment
Identify which of our benchmarking task types closely aligns with your specific application.
Step 2: Top 3 Model Selection
Based on your criteria, select the top three performing models for your identified task. Consider factors like performance, cost, and privacy in line with your objectives.
Step 3: Exploration of New Models
Expand your model pool by including any additional models that may perform well in your application context. This proactive approach ensures a more comprehensive evaluation.
Step 4: Data Preparation
Create a high-quality evaluation dataset using real-world data relevant to your task. Ensure this dataset reflects the challenges and nuances expected in production.
Step 5: Performance Evaluation
Conduct a thorough evaluation of the selected models with your prepared dataset. Assess their performance using relevant metrics to gain a well-rounded understanding of each model's strengths and weaknesses.
By adhering to these steps, you’ll be sure to choose the right model for your use case.
Conclusion
We hope this post helps you choose the right LLM for your RAG use case. By evaluating models based on cost-performance-security tradeoffs, enterprises can make informed decisions to enhance their AI solutions. Whether opting for open-source flexibility or closed-source reliability, the right LLM can significantly improve the accuracy and relevance of generated responses, setting you up for long-term success.
Ready to dive deeper? Explore our comprehensive Mastering RAG eBook (it's free).


Pratik Bhavsar