
When our daily life is driven by search and coding agents, it is super clear to see how important they are becoming. This momentum is reflected in market projections: the global Al agents market is projected to grow from USD 7.84 billion in 2025 to USD 52.62 billion by 2030 at a CAGR of 46.3% during the forecast period. Most enterprises are planning to effectively utilize AI Agents in their workflows due to the increased reliability of LLMs and reduced inference costs.
Yet as they rush to implement these autonomous systems, a critical challenge emerges: How do you transform experimental agent projects into reliable production systems that deliver on this technology's economic promise?
Let’s dive deep into the topic and learn how to build systems for agents that perform reliably without surprises.

The Hidden Complexity of Agent Evaluation
AI agents introduce unique evaluation and testing challenges that few engineering teams are prepared to address. These systems operate on non-deterministic paths, capable of solving the same problem in multiple ways. Consider a customer service agent that might approach identical issues through entirely different resolution strategies, making traditional testing methodologies insufficient.
The complexity extends across multiple potential failure points:
An LLM planner might misunderstand a task's intent, leading to a cascade of subsequent errors
The agent might select inappropriate tools or fail to execute chosen tools due to parameter misalignment
Even with perfect execution, the final action might not address the user's actual need due to misinterpreting the original request
Traditional test methodologies that rely on linear execution paths and deterministic outcomes are ineffective in this environment. A new evaluation paradigm is needed.
These challenges directly affect developer productivity, agent reliability, and business outcomes. In production environments, AI failures result in frustrated customers, lost revenue, and eroded trust. While consumers express annoyance with traditional customer service transfers, AI agents have the potential to alleviate these issues—but only if they operate reliably.
Building Your Agent Evaluation Flywheel
The true power of agent evaluation metrics lies not just in measuring performance, but in creating a self-reinforcing improvement cycle. Galileo's platform enables this "evaluation flywheel" through an integrated suite of features specifically designed for AI agents.
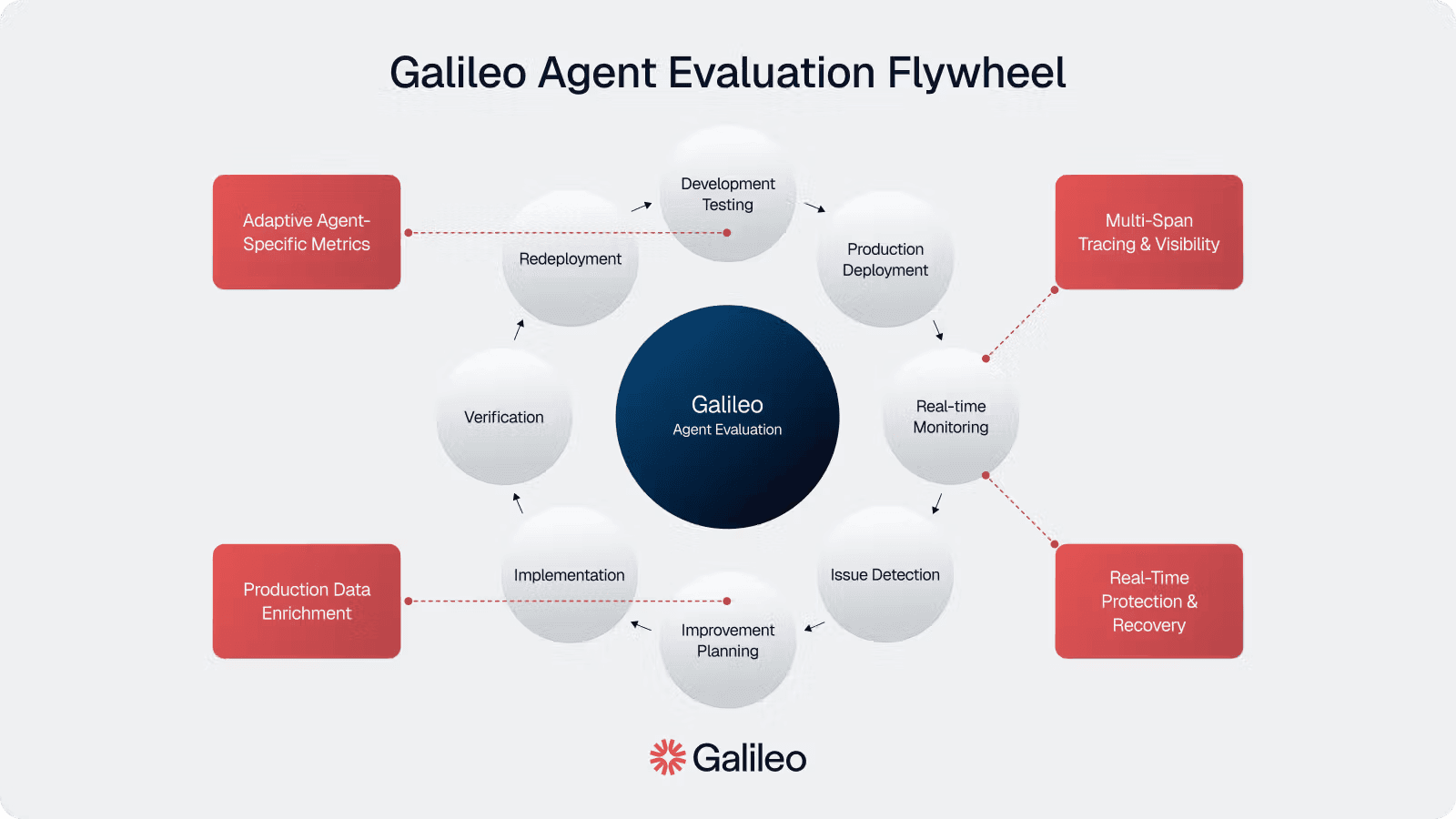
The Continuous Improvement Cycle
A successful agent evaluation flywheel combines pre-deployment testing, production monitoring, and post-deployment improvement in a seamless cycle:
Development Testing: Validate agent performance in controlled environments
Production Deployment: Release agents with confidence based on pre-deployment metrics
Real-time Monitoring: Track performance across all key dimensions in production
Issue Detection: Identify patterns and root causes of problems
Improvement Planning: Prioritize fixes based on frequency and impact
Implementation: Apply targeted improvements to address specific issues
Verification: Confirm fixes work using controlled experiments
Redeployment: Release enhanced versions with measured improvements
What makes this a true flywheel is how production data feeds back into development, creating momentum where each improvement cycle builds upon the last. Galileo's platform is purpose-built to enable this virtuous cycle with seamless connections between production monitoring, issue detection, and development environments.
Galileo's Differentiating Capabilities
1. Adaptive Agent-Specific Metrics
Galileo's evaluation platform includes research-backed metrics specifically designed for agentic systems:
Tool Selection Quality: Evaluates whether agents select appropriate tools with correct arguments
Tool Error Detection: Identifies execution failures in specific tools or API calls
Action Advancement: Measures whether each step progresses toward user goals
Action Completion: Determines if final actions successfully resolve user requests
What truly sets these metrics apart is their adaptability through Continuous Learning with Human Feedback (CLHF). Teams can customize generic metrics to their specific domain with as few as five annotated examples, improving accuracy by up to 30% and reducing metric development from weeks to minutes.
Galileo's proprietary ChainPoll technology scores each trace multiple times at every step, ensuring robust evaluations that significantly outperform traditional methods like RAGAS in side-by-side comparisons.
2. End-to-End Visibility Through Multi-Span Tracing

Galileo's trace visualization solves the challenge of understanding complex agent workflows:
Unified Trace View: See entire conversation flows from initial request to final response
Step-by-Step Inspection: Examine each component of the agent workflow individually
Error Localization: Pinpoint exactly where in a complex chain issues occur
Performance Metrics: Track token usage, latency, and costs at both the step and workflow levels
This comprehensive visibility eliminates the need to manually piece together information from disparate logs, dramatically accelerating debugging and optimization.
3. Real-Time Protection and Recovery
Beyond passive monitoring, Galileo provides active safeguards to prevent user-facing failures:
Pre-Response Validation: Apply evaluation metrics to outgoing responses in real-time
Threshold-Based Intervention: Define acceptable performance levels for critical metrics
Graceful Degradation: Implement fallback strategies when issues are detected
Human Review Triggering: Route edge cases to human experts based on confidence scores
These protection mechanisms not only prevent negative user experiences but also generate valuable data for continuous improvement.
4. Production Data Enrichment
Galileo's platform excels at transforming real-world usage into actionable insights:
Automatic Pattern Detection: Identify common failure modes across production interactions [feature is in testing and will be launched soon]
Dataset Creation: Turn production examples into structured test datasets
Edge Case Cataloging: Build libraries of challenging scenarios from real user interactions
Regression Prevention: Ensure new changes don't reintroduce previously fixed issues
This capability closes the loop between production and development, ensuring that real user experiences directly inform improvement priorities.
Practical Implementation Steps
To implement an effective evaluation flywheel with Galileo:
Start with the Playground: Use Galileo's interactive environment to rapidly test different prompt configurations before deployment
Build Comprehensive Test Datasets: Organize evaluation examples into structured datasets using Galileo's dataset management tools
Deploy with Confidence: Use Galileo's pre-deployment metrics to verify agent readiness for production
Monitor Production Performance: Set up dedicated log streams for organized visibility into real-world performance
Enable Domain Expert Feedback: Leverage Galileo's annotation interface to capture insights from subject matter experts without requiring technical skills
Create a Post-Deployment Data Pipeline: Configure automatic dataset creation from production examples to continuously enrich testing
Implement Automated Protection: Configure real-time safeguards based on your critical evaluation metrics
By implementing this systematic approach, engineering teams can transform experimental agents into reliable, continuously improving production systems. The Galileo platform doesn't just help identify problems—it provides the infrastructure to solve them efficiently and verify improvements in a measurable way.
Evaluation Framework

The most effective evaluation frameworks emphasize dimensions that predict real-world success. Based on our work with forward-thinking companies, we have identified six critical metrics that, together, provide a comprehensive view of agent performance.
Tool Selection Quality
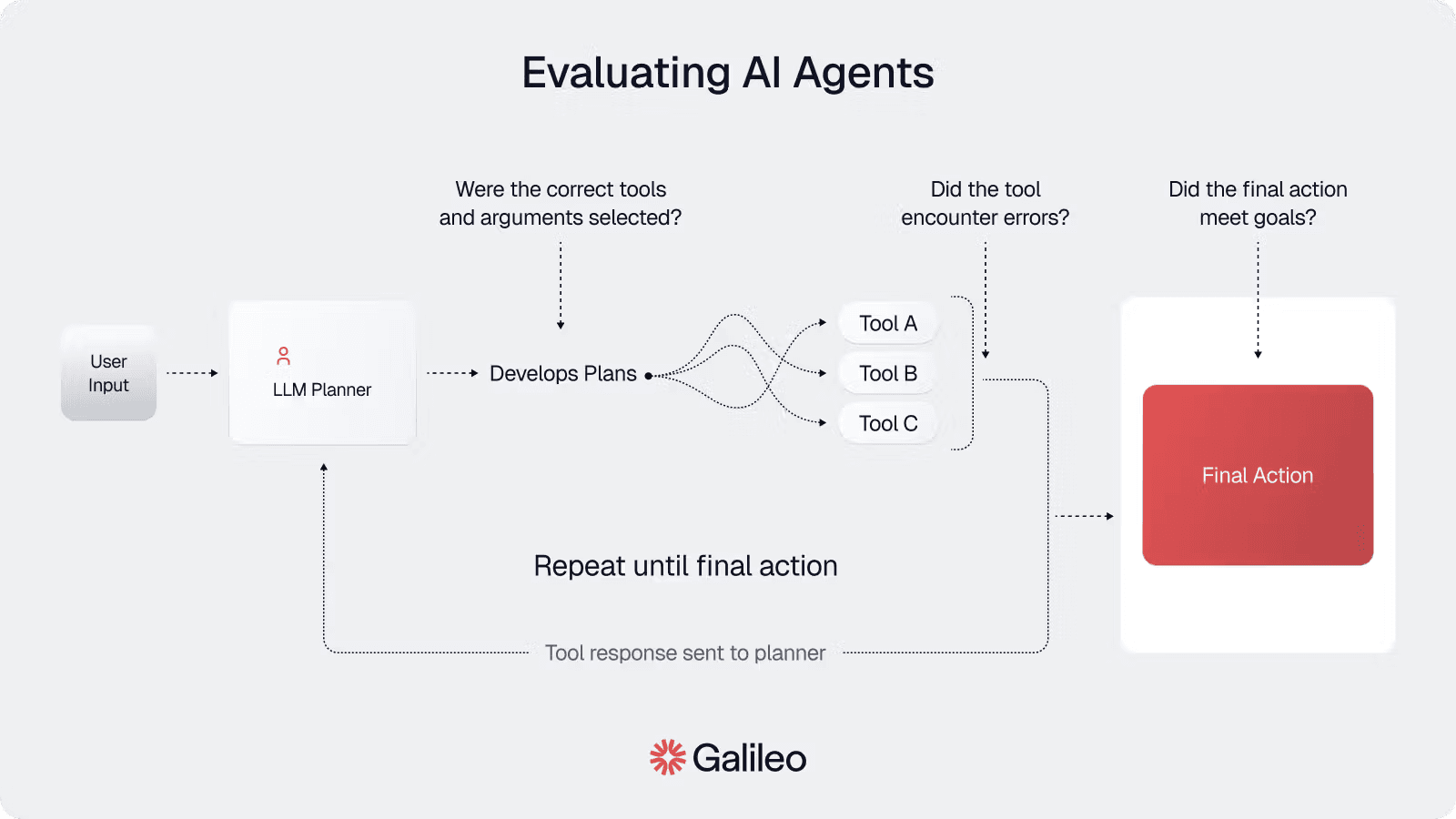
Definition: Measures whether an agent selects the correct tools with the appropriate parameters to accomplish user goals.
When an agent faces a user request, it must first decide which tools to use. This decision fundamentally shapes everything that follows. Poor tool selection can lead to ineffective responses or wasted computational resources, even if every other component works perfectly.
Calculation Method:
Evaluation requests analyze the agent's tool selection decisions
LLM evaluators assess whether selected tools and parameters were appropriate for the task
Multiple evaluations ensure robust consensus
The final score represents the ratio of appropriate selections to total decisions
Real-World Examples: In customer service scenarios, where retailers are deploying AI agents for personalized experiences, tool selection failures directly impact customer satisfaction and trust. For example, when a customer asks about a missing delivery, an agent that selects the order status tool instead of the shipment tracking tool will provide information about payment processing rather than package location—leaving the customer's actual concern unaddressed. Similarly, in financial services applications, an agent that selects a general account overview tool instead of a transaction dispute tool could provide irrelevant information when a customer is reporting fraud, potentially delaying critical security measures.
Agent failures can originate from a single misclassification step at the beginning of their workflow. By implementing more robust evaluation of tool selection, enterprises can take their agent one step further to complete reliability.
Ways to improve it:
Provide detailed documentation for each tool, including when to use it
Implement validation for tool parameters to prevent incorrect usage
Monitor which tools are frequently misused to identify improvement opportunities
Fine-tune with examples of correct tool usage in different scenarios
Our Agent Leaderboard evaluates agent performance using Galileo’s tool selection quality metric to clearly understand how different LLMs handle tool-based interactions across various dimensions.

Action Advancement
Definition: Measures whether an assistant successfully makes progress toward at least one user goal.
Action Advancement captures the incremental progress an agent makes, even when complete resolution isn't achieved in a single interaction. This metric is crucial for complex, multi-step tasks where partial progress still provides value.
An assistant successfully advances a user's goal when it:
Provides a complete or partial answer to the user's question
Requests clarification or additional information to better understand the user's needs
Confirms that a requested action has been successfully completed
Calculation Method:
Multiple evaluation requests analyze the assistant's progress toward user goals
A specialized chain-of-thought prompt guides assessment of progress
Each evaluation produces both an explanation and a binary judgment
The final score represents the percentage of interactions that advanced user goals
Real-World Examples: In retail environments, where companies leverage AI agents for revenue growth through personalized experiences, Action Advancement directly correlates with conversion rates. When an agent successfully advances a customer toward purchase decisions—even incrementally—it builds confidence and engagement. In a customer service context, each advancement step reduces the likelihood that users will abandon the interaction, improving resolution rates and customer satisfaction.
Ways to improve it:
Track advancement scores across different types of user requests to identify patterns
Analyze failure cases to understand where agents struggle to make progress
Combine with other metrics to build a comprehensive view of agent effectiveness
Test with complex, multi-step tasks to thoroughly assess advancement capabilities

Tool Error
Definition: Detects errors or failures during the execution of tools.
Even when an agent selects the right tools, execution can fail for numerous reasons: API outages, permission issues, timeout problems, or invalid parameter combinations. Tool Error detection helps identify these execution failures before they impact user experience.
Calculation Method:
Evaluation requests analyze tool execution outcomes
Detailed analysis of execution logs identifies potential issues
The system assesses errors, exceptions, and unexpected behaviors
A comprehensive explanation describes detected errors and their potential impact
Real-World Example: In financial services, tool execution errors during transaction processing can create compliance risks and customer trust issues.
Ways to improve it:
Implement robust error handling in all tools
Add parameter validation before execution to prevent runtime errors
Monitor external dependencies that tools rely upon
Design tools with fallback mechanisms when primary execution paths fail
Action Completion
Definition: Determines whether the assistant successfully accomplished all of the user's goals.
While Action Advancement measures incremental progress, Action Completion evaluates whether the agent fully resolved the user's request. This is the ultimate measure of success—did the user get what they needed?
Calculation Method:
Evaluation requests assess whether all user goals were completely addressed
Analysis considers both explicit and implicit user requests
The system evaluates if responses are coherent, factually accurate, and complete
The final score represents the percentage of fully resolved user requests
Real-World Examples : In customer service contexts, completion rates directly impact resolution metrics and customer satisfaction. In IT support, where agents increasingly handle first-tier support requests, completion rates determine how many tickets can be resolved without human escalation, directly impacting support costs and team productivity.
Ways to improve it:
Build capabilities to detect when user requests have multiple parts
Implement verification steps to ensure all aspects of a request are addressed
Create recovery mechanisms when partial completion occurs
Train agents to summarize what was accomplished to provide completion clarity
Instruction Adherence
Definition: Measures whether a model followed the system or prompt instructions when generating a response.
Instruction Adherence evaluates how well the agent's behavior aligns with its defined guardrails and operating parameters. This metric is particularly important for ensuring agents stay within their intended scope and follow critical business rules.
Calculation Method:
Multiple evaluation requests analyze whether responses follow provided instructions
A specialized prompt guides detailed evaluation of adherence to specific instructions
The system collects multiple assessments to ensure robust evaluation
The final score represents the ratio of adherent responses to total interactions
Real-World Impact: In regulated industries such as healthcare, financial services, and legal technology, adherence to instructions directly impacts compliance risk. An agent that ignores instructions to maintain privacy, follow regulatory guidelines, or disclose required information can create significant liability.
In HR applications, where AI agents now automate resume screening tasks, instruction adherence ensures fair and consistent application of hiring criteria, reducing bias and improving hiring outcomes.
Ways to improve it:
Write clear, specific instructions without ambiguity
Place critical instructions prominently in your prompt
Monitor adherence across different types of instructions to identify patterns
Implement guardrails to prevent non-compliant responses from reaching users
Context Adherence
Definition: Measures whether a model's response correctly utilizes and references the provided context.
Context Adherence evaluates how effectively an agent uses available information sources, such as retrieved documents, conversation history, or system data. This metric helps identify hallucination issues where agents generate information not supported by available context.
Calculation Method:
Evaluation requests analyze how well responses utilize provided context
The system assesses for factual consistency with source materials
Multiple evaluations ensure robust consensus
The final score represents the ratio of context-adherent responses to total responses
Real-World Impact: In knowledge-intensive domains like legal research, medical diagnosis, or financial analysis, context adherence directly impacts the accuracy and reliability of agent outputs. When agents fail to adhere to provided context, they may generate misleading or incorrect information that appears authoritative, creating serious risk.
Ways to improve it:
Improve retrieval mechanisms to provide more relevant context
Implement citation mechanisms to trace information sources
Develop specialized prompts that emphasize source fidelity
Create verification mechanisms for fact-checking outputs against context
Best Practices for Agent Development
Galileo's approach to agent evaluation and improvement aligns closely with best practices outlined by industry leaders like Anthropic. Let's examine how Galileo's features support these recommended patterns for building effective agents:
Finding the Simplest Solution First
Anthropic recommends "finding the simplest solution possible, and only increasing complexity when needed." Galileo supports this philosophy by:
Providing detailed metrics that help teams understand whether increased prompt or architecture complexity is warranted
Enabling rapid experimentation to compare simpler workflows against more complex agent architectures
Offering visibility into cost and latency impacts of different approaches
For many applications, a single well-prompted LLM call with retrieval might be sufficient. Galileo's evaluation framework helps teams determine when this simpler approach works—and when they genuinely need the additional complexity of an agent.
Balancing Workflows and Agents
Anthropic distinguishes between two architectural patterns:
Workflows: Systems where LLMs and tools are orchestrated through predefined code paths
Agents: Systems where LLMs dynamically direct their own processes and tool usage
Galileo's metrics help teams make informed decisions about which approach best fits their use case. The Tool Selection Quality metric reveals whether an agent is making appropriate choices dynamically, while the Action Advancement metric shows whether progress is being made toward user goals. These insights help teams determine where fixed workflows might be more reliable and where agent flexibility adds value.
What are the Takeaways?
As AI continues to transform how businesses operate, engineering leaders must approach agent evaluation with the same rigor as traditional software systems.
Building effective agents requires attention to the entire development process, from initial experimentation to production monitoring. Galileo's end-to-end platform supports:
Early experimentation: Experimentation tools for rapid iteration
Systematic testing: Structured datasets and metrics for reliable evaluation
Production monitoring: Comprehensive logging and visualization for real-world performance
Continuous improvement: The complete flywheel from issue detection to verification of fixes
This integrated approach prevents the common pitfall of focusing exclusively on development while neglecting production monitoring—or vice versa.
Galileo's Agent Evaluation helps teams like Cisco, Twilio, ServiceTitan, and Reddit implement these practices, providing visibility into agent performance across multiple dimensions and enabling the confidence needed for production deployment. Learn more about our state-of-the-art evaluation capabilities by chatting with our team.

Pratik Bhavsar